類別變項次數分佈
使用gtsummary套件中的tbl_summary()呈現類別變項的次數分佈。若要呈現交叉表(cross table),則使用tbl_cross()。
df %>%
dplyr::select(居住地) %>%
tbl_summary(missing_text = "NA") %>%
as_flex_table() %>% #指定以flextable格式輸出
set_caption("居住地次數分布")
Characteristic | N = 2,0721 |
|---|
居住地 |
|
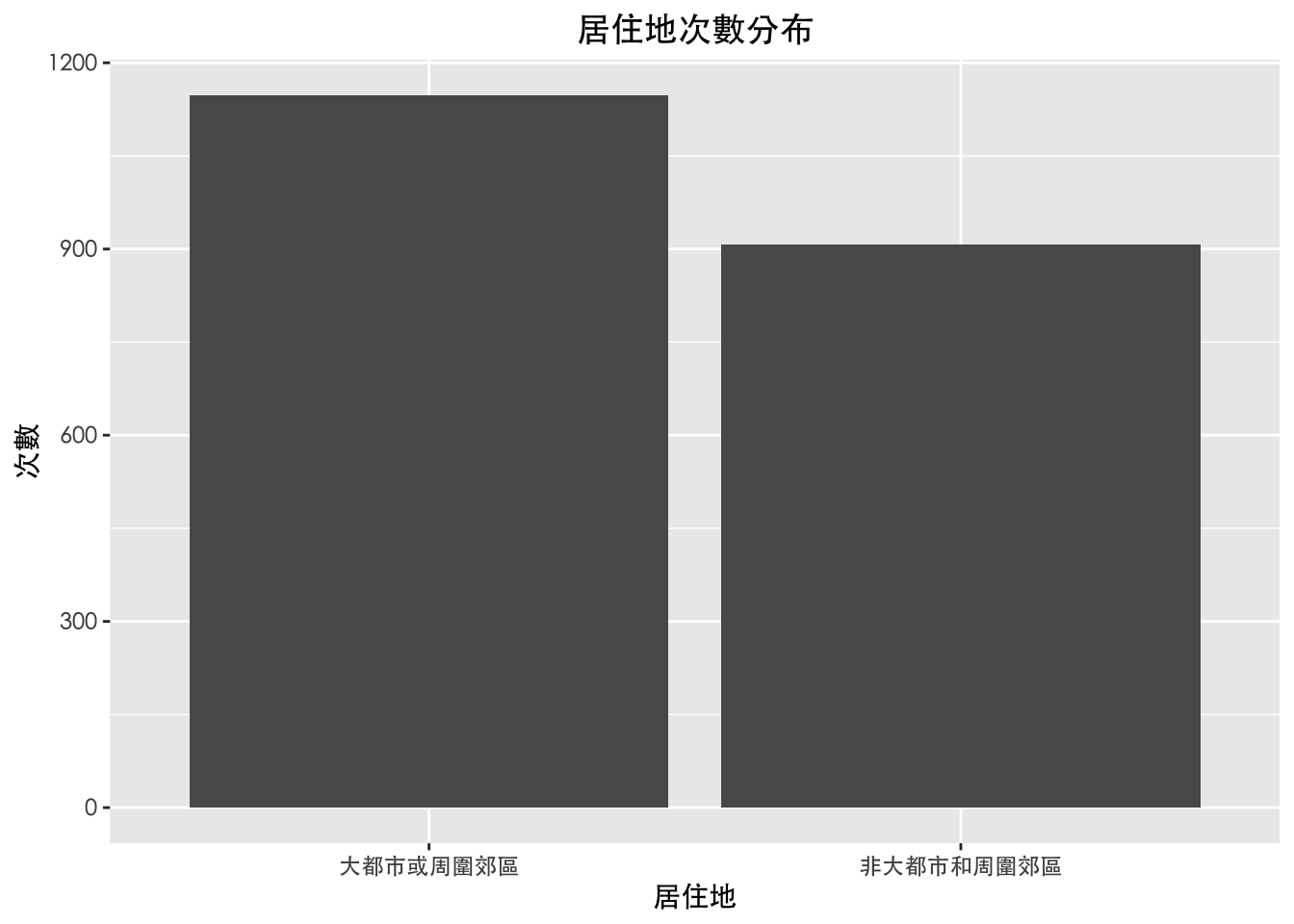
大都市或周圍郊區 | 1,148 (56%) |
非大都市和周圍郊區 | 907 (44%) |
NA | 17 |
1n (%) |
df %>%
tbl_cross(row = 年齡分組,
col = 同性戀結婚,
missing_text = "NA") %>%
as_flex_table() %>%
set_caption("同性戀結婚支持與否與年齡分組的交叉表")
| 同性戀結婚 | |
|---|
| 表態贊成者 | 非表態贊成者 | Total |
|---|
年齡分組 |
|
|
|
40歲(含)以下 | 638 | 241 | 879 |
41~60歲 | 352 | 405 | 757 |
61歲(含)以上 | 99 | 337 | 436 |
Total | 1,089 | 983 | 2,072 |
df %>%
drop_na(居住地) %>%
ggplot(aes(x=居住地)) +
geom_bar() +
labs(
y = "次數",
title = "居住地次數分布"
) +
theme(
text = element_text(family = "微軟正黑體"),
plot.title = element_text(hjust = 0.5)
)
數值變項描述統計
使用modelsummary套件中的datasummary()呈現數值變項描述統計表,指定呈現樣本數N(不計遺漏值)、平均數Mean、標準差SD、中位數Median、最小值Min與最大值Max。也可以指定分組,呈現分組平均數。
datasummary(同性戀開放度 ~ N+Mean+SD+Median+Min+Max,
data = df,
out = "flextable", #指定以flextable格式輸出
title = "同性戀開放度描述統計表")
| N | Mean | SD | Median | Min | Max |
|---|
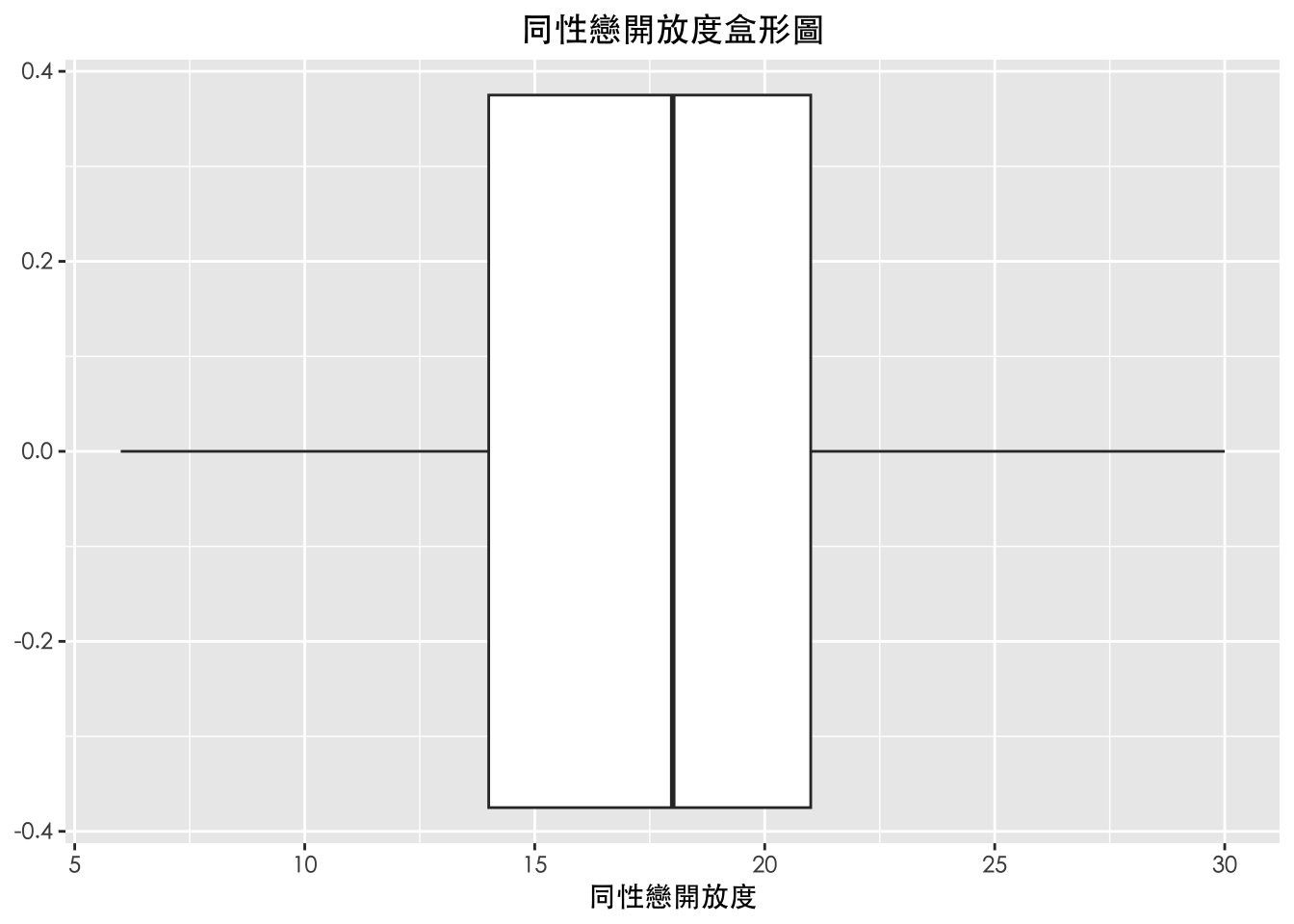
同性戀開放度 | 1747 | 17.59 | 4.55 | 18.00 | 6.00 | 30.00 |
df %>%
drop_na(同性戀開放度) %>%
ggplot(aes(x=同性戀開放度)) +
geom_boxplot() +
labs(
title = "同性戀開放度盒形圖"
) +
theme(
text = element_text(family = "微軟正黑體"),
plot.title = element_text(hjust = 0.5)
)
#可分組
datasummary(同性戀開放度 ~ 居住地*(Mean),
data = df,
out = "flextable",
title = "同性戀開放度平均數(按居住地分)")
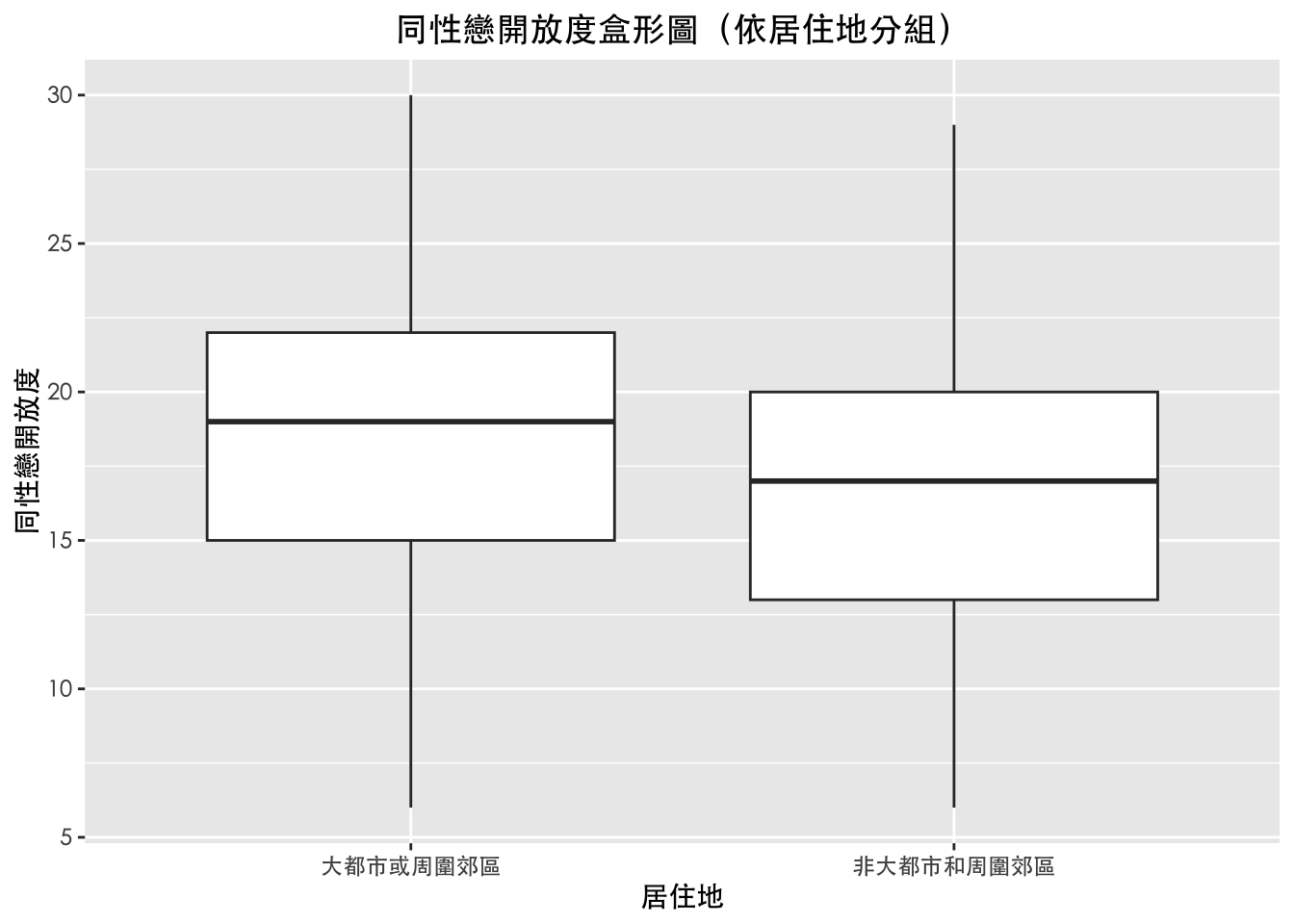
| 大都市或周圍郊區 | 非大都市和周圍郊區 |
|---|
同性戀開放度 | 18.28 | 16.71 |
df %>%
drop_na(同性戀開放度, 居住地) %>%
ggplot(aes(x = 居住地, y = 同性戀開放度)) +
geom_boxplot() +
labs(
title = "同性戀開放度盒形圖(依居住地分組)",
x = "居住地",
y = "同性戀開放度"
) +
theme(
text = element_text(family = "微軟正黑體"),
plot.title = element_text(hjust = 0.5)
)
相關係數矩陣
使用modelsummary套件中的datasummary_correlation()呈現相關係數矩陣,該函數自動呈現下三角型。
df %>%
dplyr::select(同性戀開放度, 就學年數, 性別刻板印象) %>%
drop_na() %>%
datasummary_correlation(output = "flextable",
title = "同性戀開放度、就學年數與性別刻板印象之相關矩陣")
| 同性戀開放度 | 就學年數 | 性別刻板印象 |
|---|
同性戀開放度 | 1 | . | . |
就學年數 | .30 | 1 | . |
性別刻板印象 | -.28 | -.17 | 1 |
模型結果呈現
使用modelsummary套件中的modelsummary()呈現迴歸模型結果。
model_1 <- lm(同性戀開放度 ~
就學年數 +
factor(年齡分組) +
factor(居住地),
data = df)
model_2 <- lm(同性戀開放度 ~
就學年數 +
性別刻板印象 +
factor(年齡分組) +
factor(居住地) +
就學年數 * 性別刻板印象,
data = df)
modelsummary(list(model_1,model_2),
stars = TRUE,
out = "flextable",
gof_map = c("nobs", "r.squared", "adj.r.squared"),
title = "同性戀開放度迴歸模型")
| (1) | (2) |
|---|
(Intercept) | 18.631*** | 20.004*** |
| (0.243) | (0.567) |
就學年數 | 0.164*** | 0.227* |
| (0.023) | (0.110) |
factor(年齡分組)41~60歲 | -2.003*** | -1.789*** |
| (0.230) | (0.255) |
factor(年齡分組)61歲(含)以上 | -4.429*** | -3.594*** |
| (0.304) | (0.337) |
factor(居住地)非大都市和周圍郊區 | -0.894*** | -0.775*** |
| (0.205) | (0.229) |
性別刻板印象 |
| -0.763*** |
|
| (0.225) |
就學年數 × 性別刻板印象 |
| -0.033 |
|
| (0.050) |
Num.Obs. | 1644 | 1231 |
R2 | 0.216 | 0.227 |
R2 Adj. | 0.214 | 0.223 |
+ p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 |
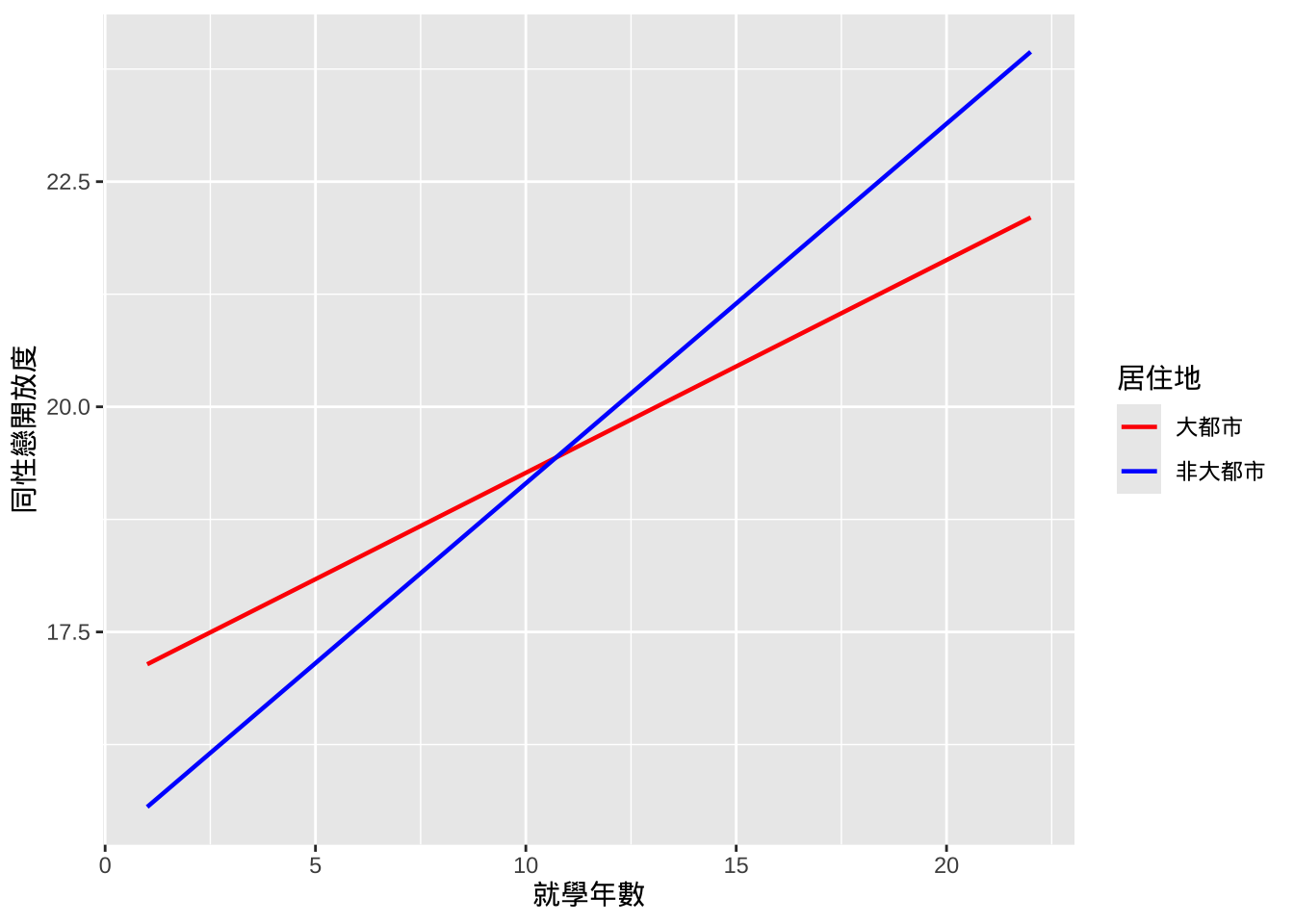
#畫分組迴歸線
df %>%
drop_na(同性戀開放度,就學年數,居住地) %>%
ggplot(aes(x=就學年數,
y=同性戀開放度,
color=居住地)) +
geom_smooth(method="lm", se = F, size =0.8)+
scale_color_manual(values=c("red","blue"), labels = c("大都市","非大都市"))